Handling Non-US-ASCII characters
If you want to use characters in your sketch that do not belong to the standard
US-ASCII character set, then you must take care about the encoding of these
characters.
Without the steps described below, you will notice that Visual Micro will
translate all foreign characters into the same three byte sequence 0xef 0xbf 0xbd.
Examples for such characters are German umlauts like Ä, Ö, Ü, or cyrillic
letters like Б.
Some Basics About Character Encoding
The binary representation for characters used in the (US-) English language
are standardized in the ASCII Standard. For all other characters and symbols,
there are several standards, one of the most common are Unicode, Windows CP1252 and UTF-8.
The gcc compiler that is used with Arduino supports UTF-8 encoding only.
UTF-8 and US-ASCII are identical for the lower 127 codes, so you don't have to
worry about character encoding if you stay with these codes and characters like
'a' to 'z', numbers etc.
For detailed information about character encoding, see the "See also" section
at the end of this page.
Specifying a character encoding
If you want to use Non-ASCII characters in your source files, then you
must first tell your IDE to be save source files in UTF-8 encoding. You can do
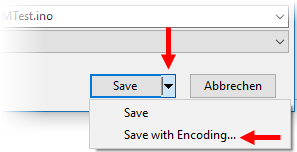
this by choosing "File > Save As" for every source
file and click on the down arrow
of the "Save" button, then choose "Save With Encoding..."
(You can simply overwrite existing files).
After choosing this menu item, you will see the Encoding Selection Window:
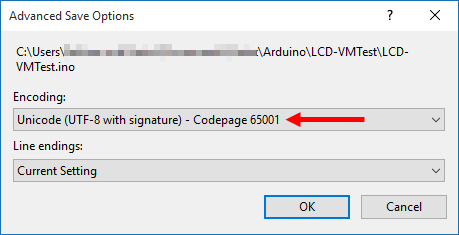
Choose "Unicode (UTF-8 with signature) - Codepage
65001" in the "Encoding" combo box, like shown
above.
Leave the "Line endings" box unchanged.
After saving your source file(s) with this method you will be able to use
foreign characters in your sketch.
Caveats with UTF-8
Language compatibility
Using UTF-8 encoded strings in your sketch is not as simple as it seems.
US-ASCII characters fit within one byte, but characters above the first 127
codes in UTF-8 need
two or even up to four bytes.
The following function call shall return a string's length.
It returns 2
(the length in bytes) but not 1 (the length in characters):
int stringLength = strlen( "Ä" );
because the character "Ä" requires 2 bytes in UTF-8.
Also, the following code will not work as expected:
char mystring[] = "Привет мир!"
if( mystring[0] == 'Ж' ) ...
mystring[0] represents one byte, but the cyrillic characters require
two bytes in UTF-8. The '==' operation only compares one byte (one char) and,
therefore, it will return true, although 'П' and 'Ж' are different characters,
because they have the same code in common for their first byte.
To handle UTF-8 encoded strings correctly, you will have to use special libraries or write
your own. If you only use strings to pass them over to a peripheral device or to
send them back via Serial.xxx functions, then you can use regular string
operations.
Does your peripheral talk UTF-8?
If you send UTF-8 encoded strings to peripherals, e.g. an LCD display, then you
must first check whether it understands UTF-8.
Many peripheral devices like 2- or 4-row alphanumeric LCD displays often have
their very own character set which only matches ASCII and UTF-8 for the lower,
common 127 codes. In such cases, it is not enough to use UTF-8 strings, you have
to write your very own code, that compares UTF-8 to the peripheral device's
encoding.
Single byte alternatives
Although the gcc compiler used by Arduino only understands UTF-8, you can trick
it by using hex codes for your special characters. In that way, you can use any
one-byte character encoding you like, like Windows codepage 1252.
Example: The German character 'ö' has character code 0xf6 in Windows-1252.
Therefore, you can write the German string "Hallöchen" as:
char greeting[] = "Hall" "\xf6" "chen";
The hex character "\xf6" and the rest of the
string are written in separate string literals (in "" pairs), otherwise
the compiler would see "\xf6c" which would result in an error. "string1"
"string2" in C++ is equivalent to "string1string2".
This is not practical for languages like Russian, where the entire
alphabet consists of "special characters", but it could be a more convenient way for languages like French or German, where most of the letters are encodable in
plain ASCII.
The main benefit of one-byte encoding is that you can use all common string and
character handling methods and functions and you will not run into effects like
those shown above.
However, also with one-byte encoding, you are responsible for proper character
handling with your peripheral devices like keyboards and displays.